Large data
This chapter provides basic guides on data manipulation within MetaCentrum infrastructure.
When dealing with data, the most important criteria is the total volume/number of files that are to be moved in a single operation.
As a rule of thumb,
- moderate data is up to 1 000 individual files AND up to 100 GB of total size,
- large data is more than any of that.
Moderate data handling
A default way to manipulate moderate data is to work through the frontend.
Example:
user123@home_PC:~$ scp user123@skirit.ics.muni.cz:/storage/brno2/home/user123/foo . # copy file "foo" from brno2 storage through skirit to a local PC
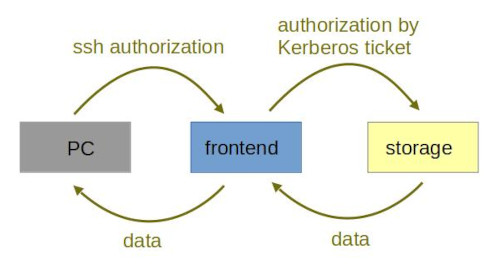
Warning
As you can see from the picture, all the traffic has to be processes by a frontend (data are not stored on frontend, but they load its CPUs and RAM), although the frontend is neither the source nor target of the data.
Large data handling
In the case of large data, the frontend should be left out of the process.
Move data to/from a storage
Example:
user123@home_PC:~$ scp user123@storage-brno2.metacentrum.cz:~/foo . # copy file "foo" from brno2 storage directly to a local PC
The overall scheme can be depicted as below:
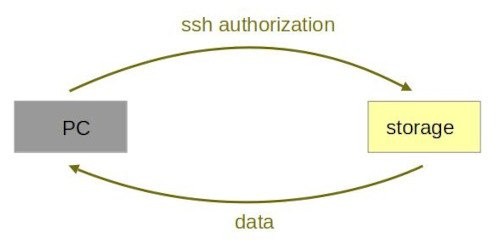
Warning
Do not use frontends to transfer large data. Processes consuming inadequate CPU and RAM frontend capacity will be stopped.
Tip
See table of storages for storage servers addresses and mount points.
Note
In general: the smaller number of files in the archive, the better (it speeds operations up and generates lower load on the storage subsystems; on the other hand, packing the files makes searching less comfortable). In case you need to archive a large number of small files, we recommend strongly to pack them before, as read/write operations are slower with many small files.
- if most of your files are large (hundreds of MBs, GBs, ...), don't bother with packing them and make a one-to-one copy to the archive,
- if your files are smaller and you don't plan to search individual files, pack them into
.taror.zipfiles, - from the technical point of view, optimal "chunk" of packed data is 500 MB or bigger,
- don't use front-end servers for anything else than moving several small files! Submit a regular job and/or take an interactive job instead to handle with the archival data.
- keep in mind that the master HOME directory of each HSM storage is dedicated just for initialization scripts, and thus has a limited quota of just 50 MB.
Move data between storages
scp
If you want to move large amount of data between storages, the setup is similar as in the case when you copy data between your PC and a storage. The only difference is the you cannot access storages interactively and therefore the scp command has to be passed as an argument to ssh command.
For example, copy file foo from plzen1 to your home at brno2:
ssh USERNAME@storage-plzen1.metacentrum.cz "scp foo storage-brno6.metacentrum.cz:~/../fsbrno2/home/USERNAME/"
If you are already logged on a frontend, you can simplify the command to:
ssh storage-plzen1 "scp foo storage-brno6:~/../fsbrno2/home/USERNAME/"
The examples shown above will run only until you either disconnect, or the validity of Kerberos ticket expires. For longer-lasting copy operations, it is a good idea to submit the scp command within a job. Prepare a trivial batch script called e.g. copy_files.sh
#!/bin/sh
#PBS -N copy_files
#PBS -l select=1:ncpus=1:scratch_local=1gb
#PBS -l walltime=15:00:00
ssh storage-plzen1 "scp foo storage-brno6:~/../fsbrno2/home/USERNAME/"
and submit it as qsub copy_files.sh.
rsync
Another option how to pass data between storages is to use rsync command.
For example, to move all your data from plzen1 to brno12-cerit:
(BUSTER)USERNAME@skirit:~$ ssh storage-plzen1 "rsync -avh ~ storage-brno12-cerit:~/home_from_plzen1/"
To move only a selected directory:
(BUSTER)USERNAME@skirit:~$ ssh storage-plzen1 "rsync -avh ~/my_dir storage-brno12-cerit:~/my_dir_from_plzen1/"
You can wrap the rsync command into a job, too.
#!/bin/sh
#PBS -N copy_files
#PBS -l select=1:ncpus=1:scratch_local=1gb
#PBS -l walltime=15:00:00
ssh storage-plzen1 "rsync -avh ~ storage-brno12-cerit:~/home_from_plzen1/"
If you then look at the output of running job you can check how the data transfer proceeds.
USERNAME@NODE:~$ tail -f /var/spool/pbs/spool/JOB_ID.pbs-m1.metacentrum.cz.OU