Fairshare
The MetaCentrum batch systems use a fairshare scheduling policy. Fairshare is a mechanism that allows historical resource utilization information to be incorporated into job feasibility and priority decisions.
- This policy tries to distribute the resources in a 'fair' way between groups and persons that are using the system. Fairshare policy adjusts dynamically job priority in a queue. Therefore, jobs are not executed in the same order as they were submitted.
- When the job belongs to a user that has used a lot of system resources (CPU, RAM, GPU and scratch disk) in past few days, the priority of the job is decreased. On the other hand, if he or she used little resources, the priority is set high and the job is placed closer to the top of the queue.
- System tracks usage of CPU, RAM, GPU, scratch disk and spec. Each such resource consumption is then normalized to its CPU-equivalent using the formula:
usage = spec*used_walltime*PE
where PE is a processor equivalent expressing how many resources (ncpus, mem, scratch, gpu...) the user has allocated on the machine and where spec is the normal spec of the main node (per cpu) on which the job runs.
- Jobs running on slower machines are thus bonused compared to those on fast machines.
- Normalized resource consumptions are summed and added to the user's Fairshare usage (total resource consumption):
Fairshare_usage += Usage_CPU + Usage_RAM + Usage_Scratch + Usage_GPU
- The time-scope of the data stored with respect to the past usage of the system is limited. Simply put, the importance of data decreases with time: yesterday is more important than the day before yesterday and so on. The memory lasts typically 30 days. The more the user has used in recent days, the lower his or her priority is.
- Importantly, the user is prioritized for publications with acknowledgement to MetaCentrum/CERIT-SC. User with a higher number of publications (reported in our system) is prioritized over users with smaller numbers of publications.
Fairshare value
Fairshare value cannot be displayed directly. Any user with queing and/or running jobs can, however, display their order as compared with other users on the MetaVO page "Users":
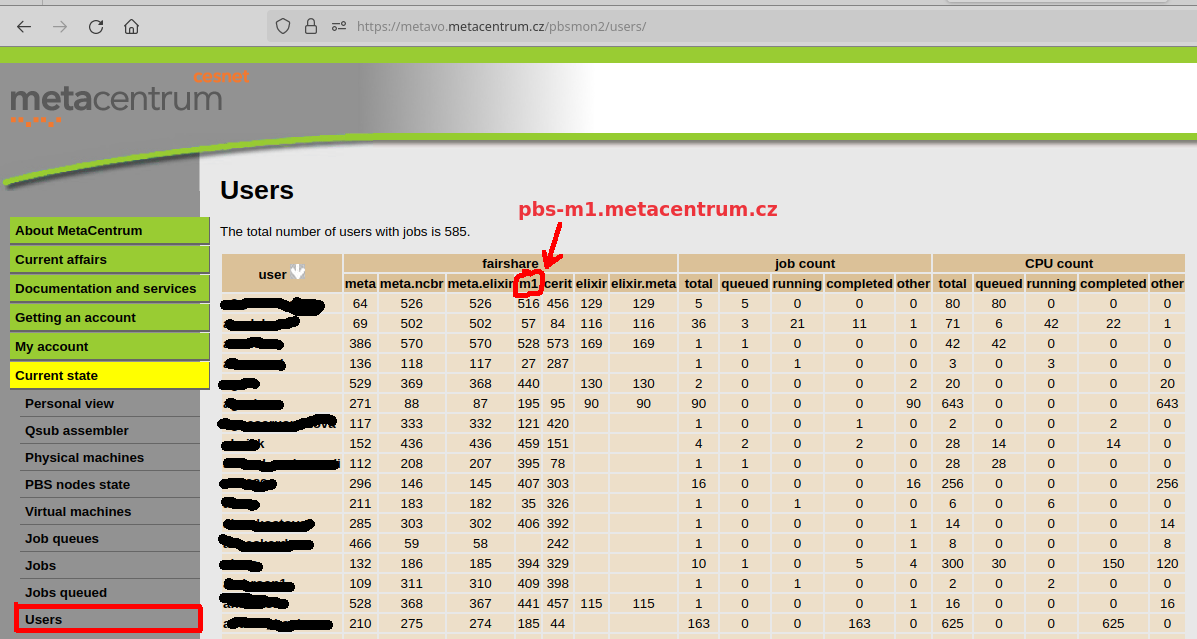
Users with lower numbers in the table have lower fairshare than users with higher values.
Tips for scheduling large jobs
Any newly started job will instantly lower the user's fairshare.
Thus, if you need to run a large job, it is not a good idea to submit simultaneously a batch of small jobs; due to internal workings of PBS, these small jobs will be prioritized over the large job (they are easier to "fill in" space), thus continuously lowering the user's fairshare. As a result, a large job may wait in the queue for a very long time.
Submit the small jobs after the large one, not together
Long story short: if you have a large job and a number of small ones, then it is better strategy to wait until the large job starts running and only then submit the small jobs. If you submit everything together, the large job may take a long time to start running.