Basic terms
Frontends, storages, homes
There are several frontends (login nodes) to access the grid. Each frontend has a native home directory on one of the storages.
There are several storages (large-capacity harddisc arrays). They are named according to their physical location (a city).
user123@user123-XPS-13-9370:~$ ssh skirit.metacentrum.cz
user123@skirit.ics.muni.cz's password:
...
(BUSTER)user123@skirit:~$ pwd # print current directory
/storage/brno2/home/user123 # "brno2" is native storage for "skirit" frontend
List of frontends together with their native /home directories
| Frontend address | Aliased as | Native home | OS | Physically located in | Note |
|---|---|---|---|---|---|
| zenith.cerit-sc.cz | zenith.metacentrum.cz | /storage/brno12-cerit | Debian 12 | Brno | |
| nympha.meta.zcu.cz | nympha.metacentrum.cz, nympha.zcu.cz, minos.zcu.cz, minos.meta.zcu.cz, alfrid.meta.zcu.cz |
/storage/plzen1 | Debian 12 | Plzen | |
| skirit.ics.muni.cz | skirit.metacentrum.cz | /storage/brno2 | Debian 12 | Brno | |
| tarkil.grid.cesnet.cz | tarkil.metacentrum.cz | /storage/praha1 | Debian 12 | Praha | |
| perian.grid.cesnet.cz | perian.metacentrum.cz, onyx.metacentrum.cz |
/storage/brno2 | Debian 12 | Brno | |
| charon.nti.tul.cz | charon.metacentrum.cz | /storage/liberec3-tul | Debian 12 | Liberec | |
| tilia.ibot.cas.cz | tilia.metacentrum.cz | /storage/pruhonice1-ibot | Debian 12 | Pruhonice | |
| zuphux.cerit-sc.cz | zuphux.metacentrum.cz | /storage/brno12-cerit | CentOS 7.9 | Brno | Serves solely as a frontend to submit to uv queue(s) from |
| elmo.elixir-czech.cz | elmo.metacentrum.cz | /storage/praha5-elixir | Debian 12 | Praha | Dedicated to Elixir users |
| oven.metacentrum.cz | /storage/brno2 | Debian 12 | Brno | Reserved to access oven node only | |
| luna.fzu.cz | luna.metacentrum.cz | /storage/praha1 | Debian 12 | Praha | Reserved for FZU users |
Frontend do's and dont's
Frontend usage policy is different from the one on computational nodes. The frontend nodes are shared by all users, the command typed by any user is performed immediately and there is no resource planning. Frontend node are not intended for heavy computing.
Frontends should be used only for:
- preparing inputs, data pre- and postprocessing
- managing batch jobs
- light compiling and testing
Warning
The resource load on frontend is monitored continuously. Processes not adhering to usage rules will be terminated without warning. For large compilations, running benchmark calculations or moving massive data volumes (> 10 GB, > 10 000 files), use interative job.
PBS servers
A set of instructions performed on computational nodes is computational job. Jobs require a set of resources such as CPUs, memory or time. A scheduling system plans execution of the jobs so as optimize the load and usage of computational nodes.
The server on which the scheduling system is called PBS server or PBS scheduler.
On the current scheduler pbs-m1.metacentrum.cz the OpenPBS is used.
The most important PBS Pro commands are:
qsub- submit a computational jobqstat- query status of a jobqdel- delete a job
Resources
Every jobs need to have defined set of computational resources at the point of submission. The resources can be specified
- on CLI as
qsubcommand options, or - inside the batch script on lines beginning with
#PBSheader.
In the PBS terminology, a chunk is a subset of computational nodes on which the job runs. In most cases the concept of chunks is useful for parallelized computing only and "normal" jobs run on one chunk. We cannot avoid the concept of chunks, though, as the specification of resources differ according to whether they can be applied on a job as a whole or on a chunk.
According to PBS internal logic, the resources are either chunk-wide or job-wide.
Job-wide resources are defined for the job as a whole, e.g. maximal duration of the job or a license to run a commercial software. These cannot be divided in parts and distributed among computational nodes on which the job runs. Every job-wide resource is defined in the form of -l <resource_name>=<resource_value>, e.g. -l walltime=1:00:00.
Chunk-wide resources can be ascribed to every chunk separately and differently.
Note
For the purpose of this intro, we assume that the number of chunks is always 1, which is also a default value. To see more complicated examples about per-chunk resource distribution, see advanced chapter on PBS resources.
Chunk-wide resources are defined as options of select statement in pairs <resource_name>=<resource_value> divided by :.
The essential resources are:
| Resource name | Keyword | Chunk-wide or job-wide? |
|---|---|---|
| no. of CPUs | ncpus | chunk |
| Memory | mem | chunk |
| Maximal duration of the job | walltime | job |
| Type and volume of space for temporary data | scratch_local | chunk |
There are a deal more resources than the ones shown here; for example, it is possible to specify a type of computational nodes' OS or their physical placement, software licences, speed of CPU, number pf GPU cards and more. For detailed information see PBS options detailed page.
Examples:
qsub -l select=1:ncpus=2:mem=4gb:scratch_local=1gb -l walltime=2:00:00 myJob.sh
where
ncpus is number of processors (2 in this example)
mem is the size of memory that will be reserved for the job (4 GB in this example, default 400 MB),
scratch_local specifies the size and type of scratch directory (1 GB in this example, no default)
walltime is the maximum time the job will run, set in the format hh:mm:ss (2 hours in this example, default 24 hours)
Queues
When the job is submitted, it is added to one of the queues managed by the scheduler. Queues can be defined arbitrarily by the admins based on various criteria - usually on walltime, but also on number of GPU cards, size of memory etc. Some queues are reserved for defined groups of users ("private" queues).
Unless you have a reason to send job to a specific queue, do not specify any. The job will be submitted into a default queue and from there routed to one of execution queues.
The default queue is only routing one: it serves to sort jobs into another queues according to the job's walltime - e.g. q_1h (1-hour jobs), q_1d (1-day jobs), etc.
The latter queues are execution ones, i.e. they serve to actually run the jobs.
In PBSmon, the list of queues for all planners can be found.

. . .
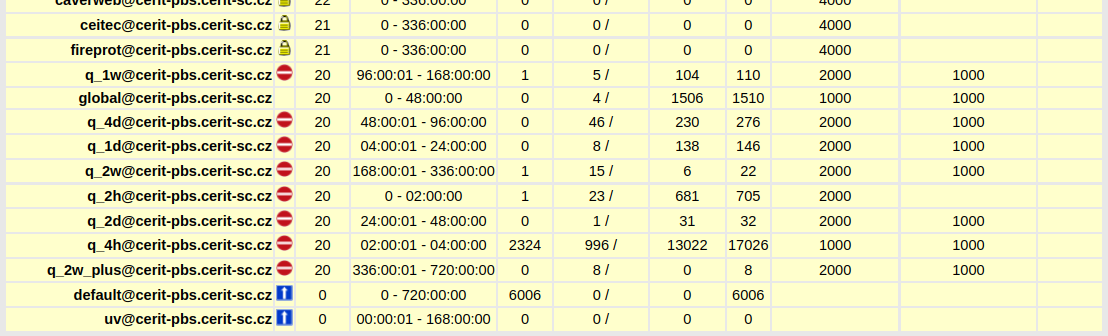
with respective meaning of icons:
| Icon | meaning |
|---|---|
| routing queue (to send jobs into) |
|
| execution queue (not to send jobs into) |
|
| private queue (limited for a group of users) |
Modules
The software istalled in Metacentrum is packed (together with dependencies, libraries and environment variables) in so-called modules.
To be able to use a particular software, you must load a module.
Key command to work with software is module, see module --help on any frontend.
Basic commands
module avail orca/ # list versions of installed Orca
module add orca # load Orca module (default version)
module load orca # dtto
module list # list currently loaded modules
module unload orca # unload module orca
module purge # unload all currently loaded modules
For more complicated examples of module usage, see advanced chapter on modules.
Scratch directory
Most application produce some large temporary files during the calculation.
To store these files, as well as all the input data, on the computational node, a disc space must be reserved for them.
This is a purpose of scratch directory on computational node.
Warning
There is no default scratch directory and the user must always specify its type and volume.
Currently we offer four types of scratch storage:
| Type | Available on every node? | Location on machine | $SCRATCHDIR value |
Key characteristic |
|---|---|---|---|---|
| local | yes | /scratch/USERNAME/job_JOBID |
scratch_local |
universal, large capacity, available everywhere |
| ssd | no | /scratch.ssd/USERNAME/job_JOBID |
scratch_ssd |
fast I/O operations |
| shared | no | /scratch.shared/USERNAME/job_JOBID |
scratch_shared |
can be shared by more jobs |
| shm | no | /dev/shm/scratch.shm/USERNAME/job_JOBID |
scratch_shm |
exists in RAM, ultra fast |
As a default choice, we recommend users to use local scratch:
qsub -I -l select=1=ncpus=2:mem=4gb:scratch_local=1gb -l walltime=2:00:00
To access the scratch directory, use the system variable SCRATCHDIR:
(BULLSEYE)user123@skirit:~$ qsub -I -l select=1:ncpus=2:mem=4gb:scratch_local=1gb -l walltime=2:00:00
qsub: waiting for job 14429322.pbs-m1.metacentrum.cz to start
qsub: job 14429322.pbs-m1.metacentrum.cz ready
user123@glados12:~$ echo $SCRATCHDIR
/scratch.ssd/user123/job_14429322.pbs-m1.metacentrum.cz
user123@glados12:~$ cd $SCRATCHDIR
user123@glados12:/scratch.ssd/user123/job_14429322.pbs-m1.metacentrum.cz$